The following are commands I use often when administering Windows 7 and Windows 10 computers in both domain (Active Directory) and non-domain (Workgroups) setups.
Religion as a Protective Factor
Religiousness is on the decline in the United States. Given that religion has played a major role in human development, I decided to look at the National Longitudinal Study of Adolescent to Adult Health to determine if lack of religiousness is associated with negative outcomes such as (but not limited to): a child’s likelihood of trying drugs or alcohol, fighting, and attempting suicide. See my original research question here.
The following series of graphs describes the entire population. Each asks a question with a two possible responses: one positive (pos) and the other negative (neg). For example, the question have you sold drugs. The positive response would be never, as selling drugs is illegal and engaging in such an activity presents a risk of damaging the child’s life outcomes.
Characteristics of the Population (Univariate Analysis)
All my variables of interest were categorical, therefore I didn’t look at center and spread characteristics, but I look at the breakdown of the positive and negative responses. For every variable, the positives out weighed the negative responses. Some responses were more dramatically split, e.g. for the question “Have you tried cocaine?” the responses were overwhelmingly no (the positive response), and for the question “Have you tried alcohol?” is nearly 50/50 yes/no positive/negative.
----------------------------------------- # of participants: 6504 ----------------------------------------- ----------------------------------------- # of non-religious individuals: 862 ----------------------------------------- ----------------------------------------- # of religious individuals: 4026 ----------------------------------------- Analysis for "Have you ever received an out-of-school suspension from school?" Distribution: pos 72.241060 neg: 27.758940 Name: H1ED7, dtype: float64 Discription: count 6488 unique 2 top Not Suspended freq 4687 Name: H1ED7, dtype: object Analysis for "Have you ever been expelled from school?" Distribution: pos 95.390071 neg: 4.609929 Name: H1ED9, dtype: float64 Discription: count 6486 unique 2 top Not Expelled freq 6187 Name: H1ED9, dtype: object Analysis for "Have you ever tried cigarette smoking, even just 1 or 2 puffs?" Distribution: pos 55.605520 neg: 44.394480 Name: H1TO1, dtype: float64 Discription: count 6449 unique 2 top Have Tried freq 3586 Name: H1TO1, dtype: object Analysis for "Have you had a alcohol more than 2 or 3 times in your life?" Distribution: pos 55.245189 neg: 44.754811 Name: H1TO12, dtype: float64 Discription: count 6444 unique 2 top Have Tried freq 3560 Name: H1TO12, dtype: object Analysis for "Have you tried marijuana?" Distribution: pos 73.446769 neg: 26.553231 Name: TRYPOT, dtype: float64 Discription: count 6406 unique 2 top (-1, 0] freq 4705 Name: TRYPOT, dtype: object Analysis for "Have you tried cocaine?" Distribution: pos 96.580262 neg: 3.419738 Name: TRYCOKE, dtype: float64 Discription: count 6404 unique 2 top (-1, 0] freq 6185 Name: TRYCOKE, dtype: object Analysis for "Have you tried inhalants?" Distribution: pos 94.268312 neg: 5.731688 Name: TRYINH, dtype: float64 Discription: count 6403 unique 2 top (-1, 0] freq 6036 Name: TRYINH, dtype: object Analysis for "Have you ever tried hard drugs like LSD, PCP, ecstasy, mushrooms speed, ice, heroin, or pills without a doctor’s prescription?" Distribution: pos 92.205561 neg: 7.794439 Name: TRYHARD, dtype: float64 Discription: count 6402 unique 2 top (-1, 0] freq 5903 Name: TRYHARD, dtype: object Analysis for "In the past 12 months, how often did you deliberately damage property that didn’t belong to you?" Distribution: pos 82.306379 neg: 17.693621 Name: PROPD, dtype: float64 Discription: count 6443 unique 2 top (-1, 0] freq 5303 Name: PROPD, dtype: object Analysis for "Have you ever shoplifted?" Distribution: pos 77.417352 neg: 22.582648 Name: SHOPL, dtype: float64 Discription: count 6443 unique 2 top (-1, 0] freq 4988 Name: SHOPL, dtype: object Analysis for "Do you often get into serious physical fights?" Distribution: pos 68.042197 neg: 31.957803 Name: FIGHT, dtype: float64 Discription: count 6446 unique 2 top (-1, 0] freq 4386 Name: FIGHT, dtype: object Analysis for "Do you sell drugs?" Distribution: pos 92.914729 neg: 7.085271 Name: SELLD, dtype: float64 Discription: count 6450 unique 2 top (-1, 0] freq 5993 Name: SELLD, dtype: object Analysis for "Have you shot or stabbed someone in the past 12 months?" Distribution: pos 98.110578 neg: 1.889422 Name: WEPVI, dtype: float64 Discription: count 6457 unique 2 top (-1, 0] freq 6335 Name: WEPVI, dtype: object Analysis for "During the past 12 months, did you attempt suicide?" Distribution: pos 71.848225 neg: 28.151775 Name: SUATM, dtype: float64 Discription: count 817 unique 2 top (-1, 0] freq 587 Name: SUATM, dtype: object
Graphical Analysis
Note the y axis is percentage. 1 = 100%.
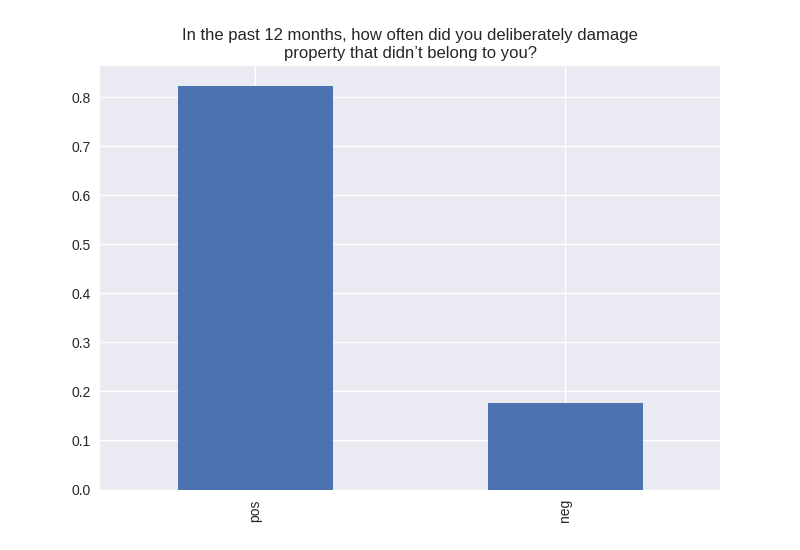
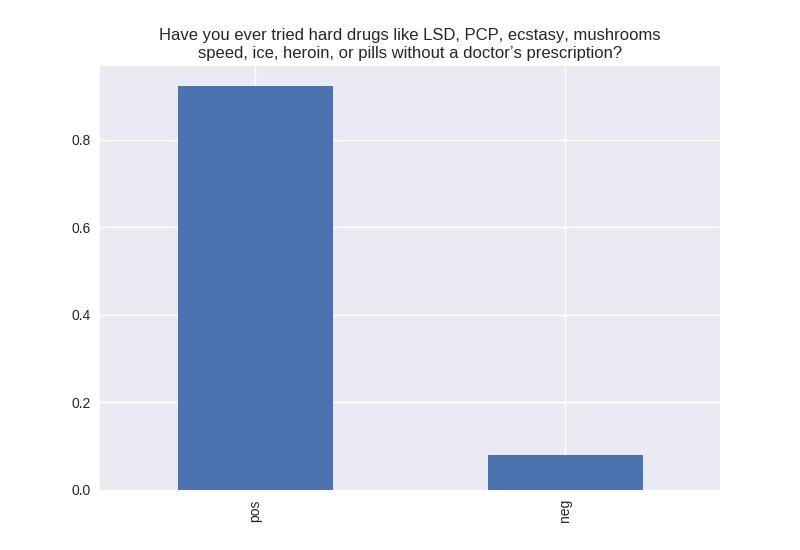
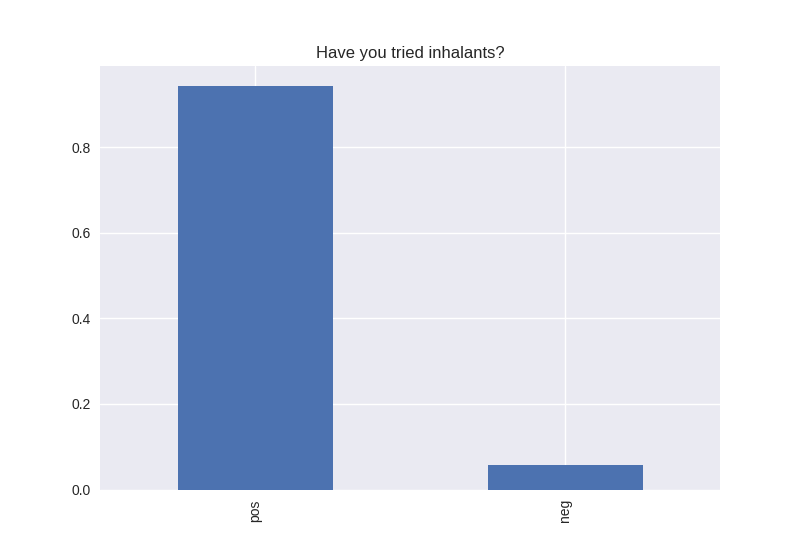
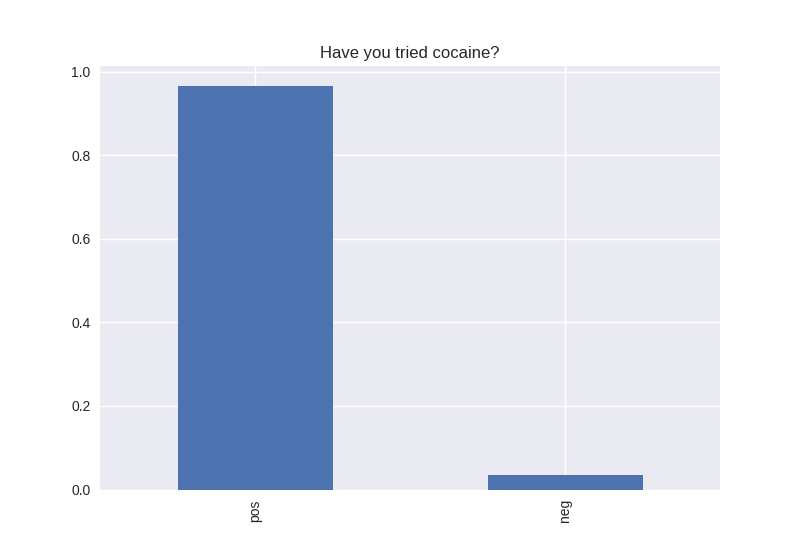
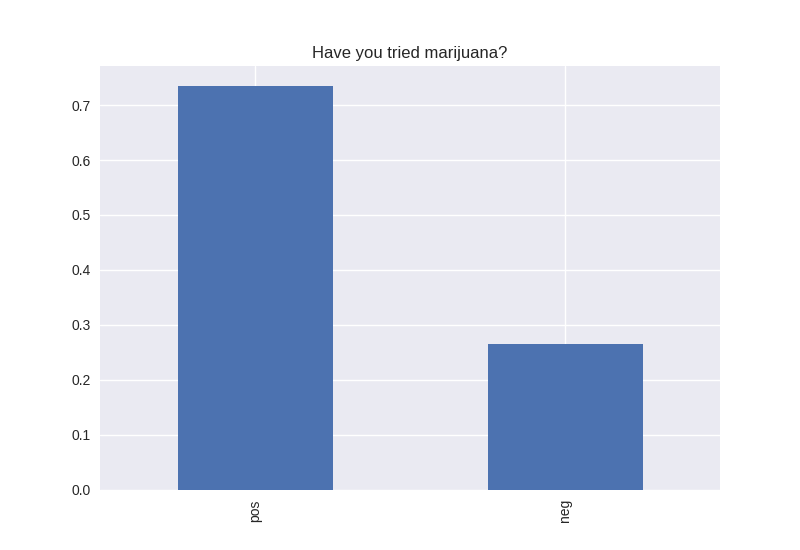
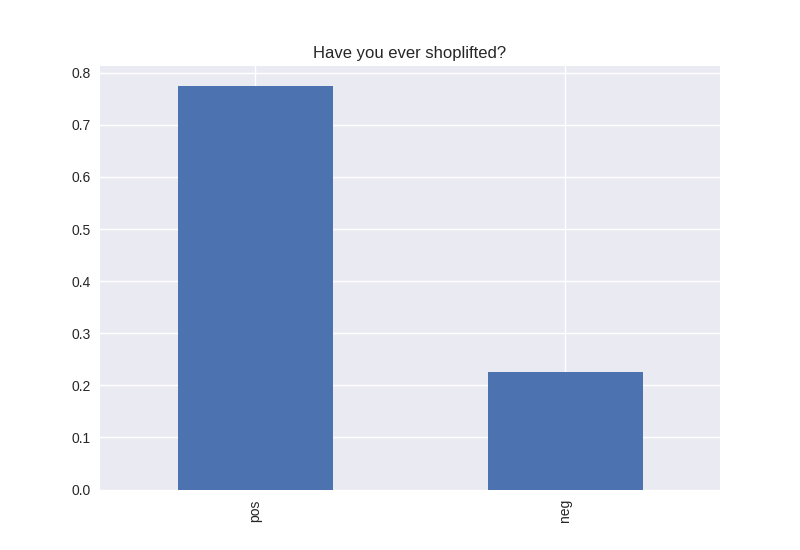
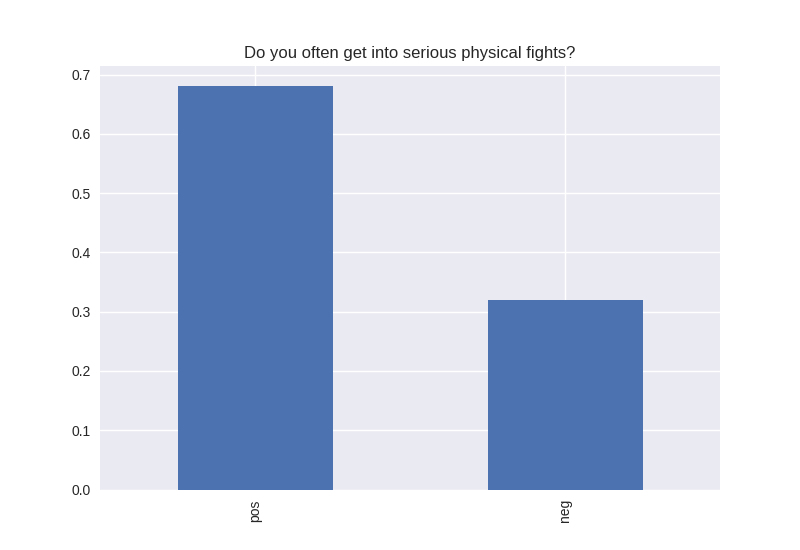
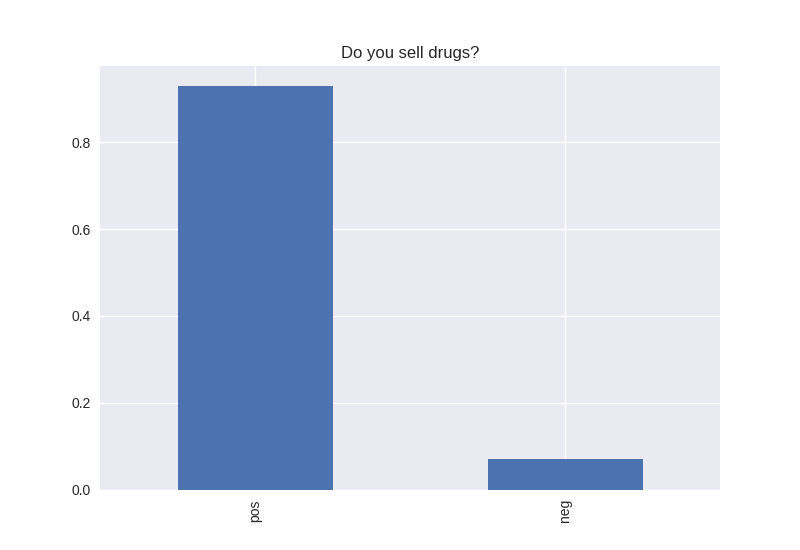
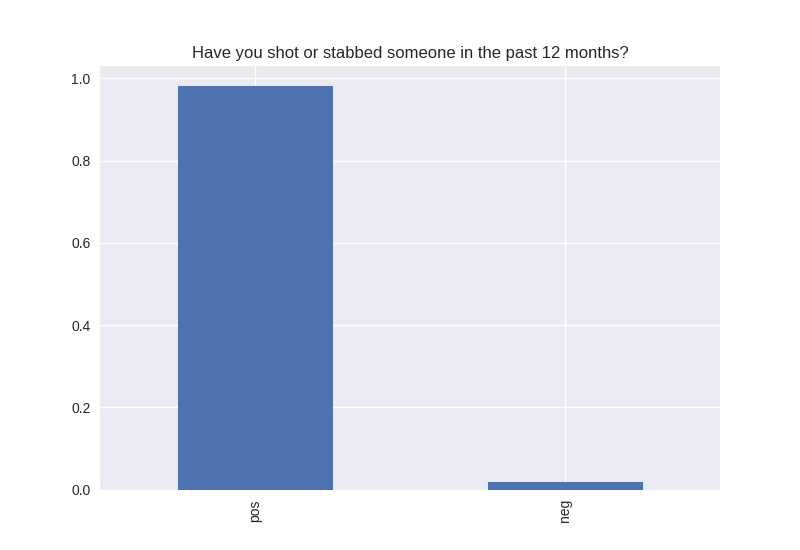
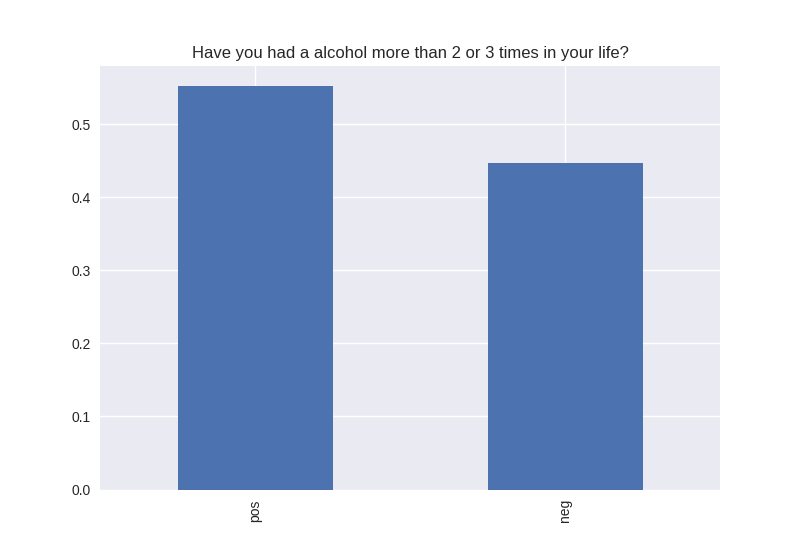
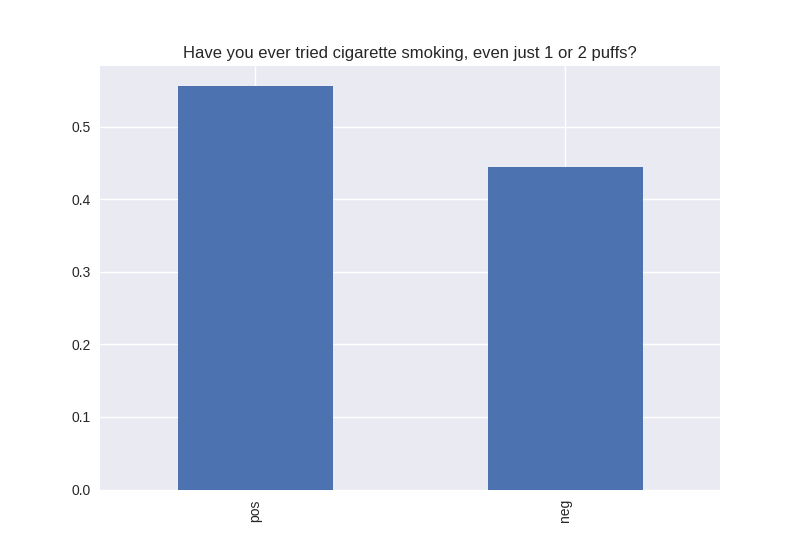
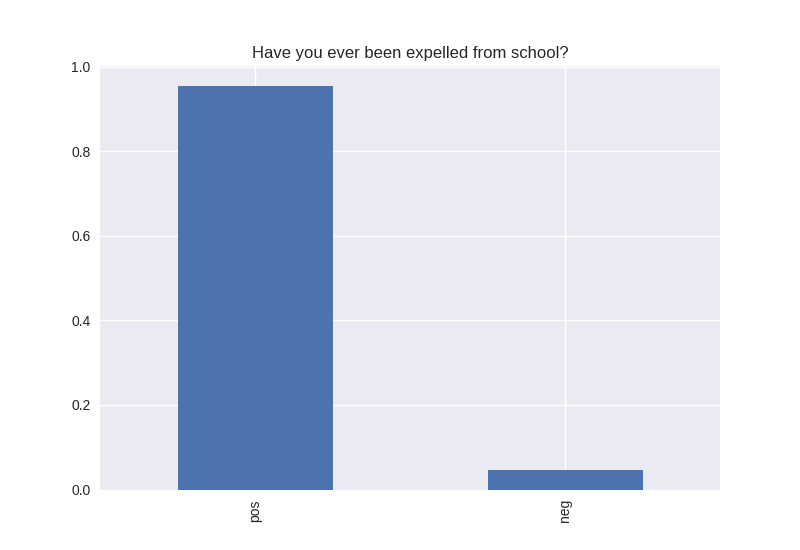
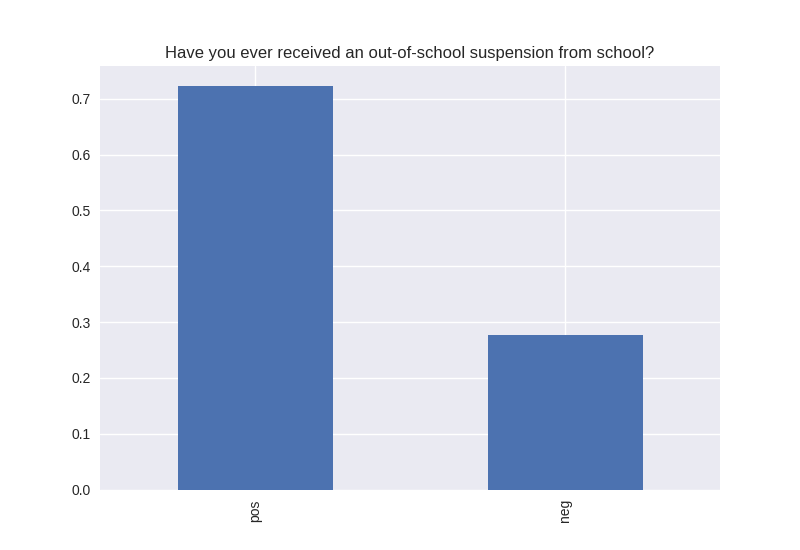
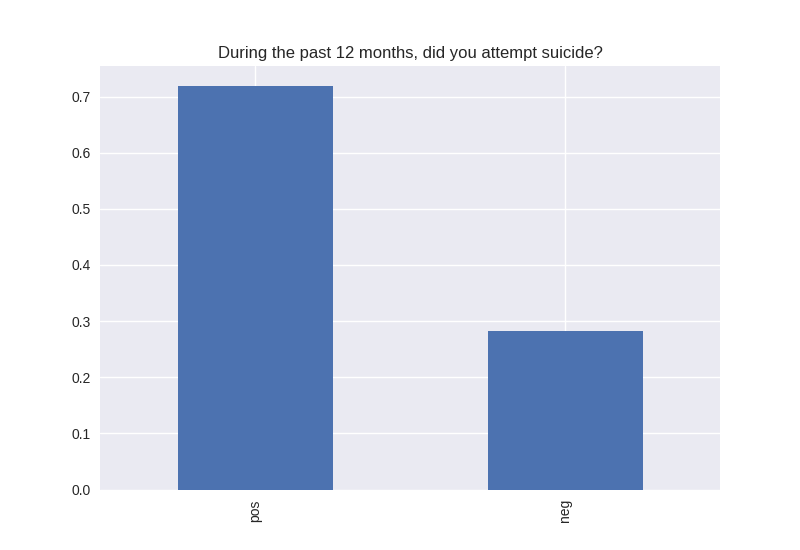
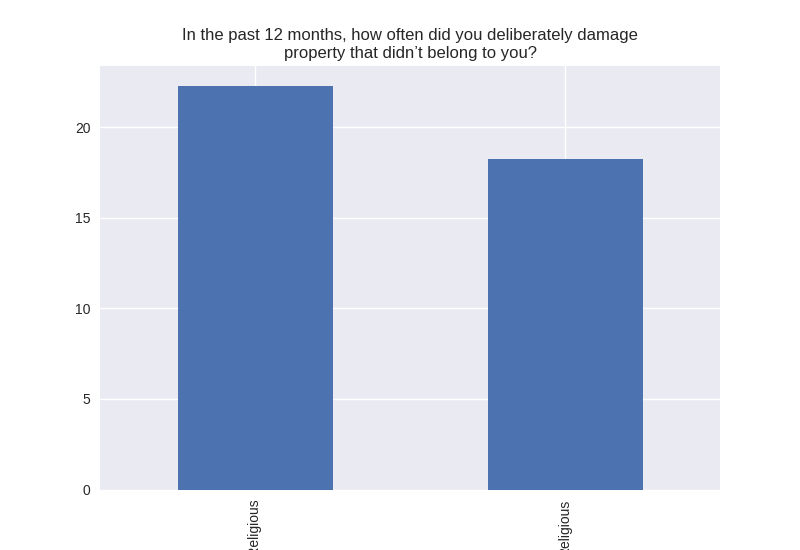
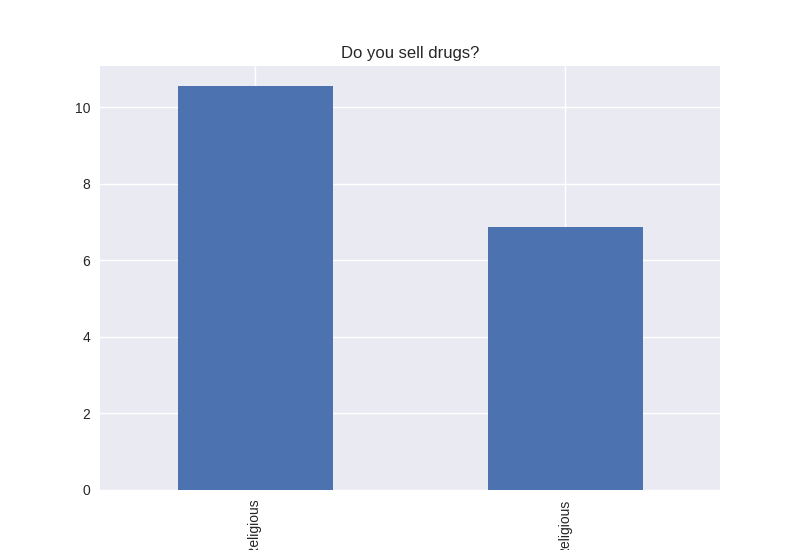
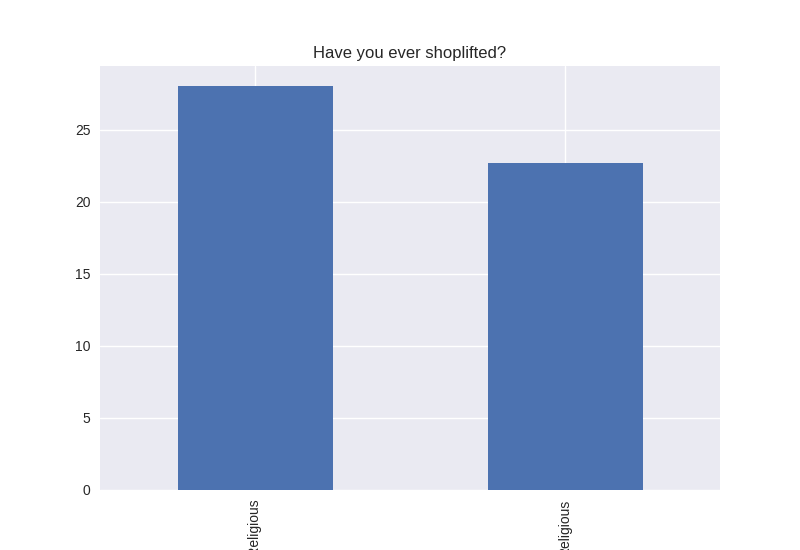
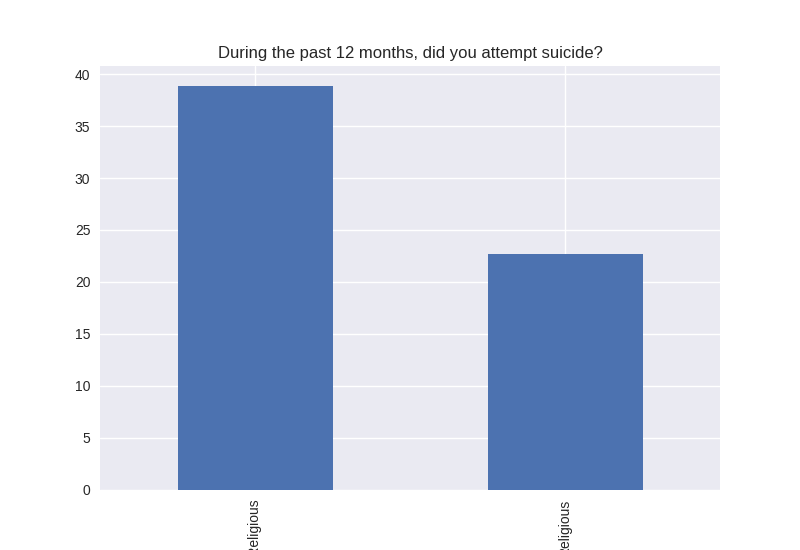
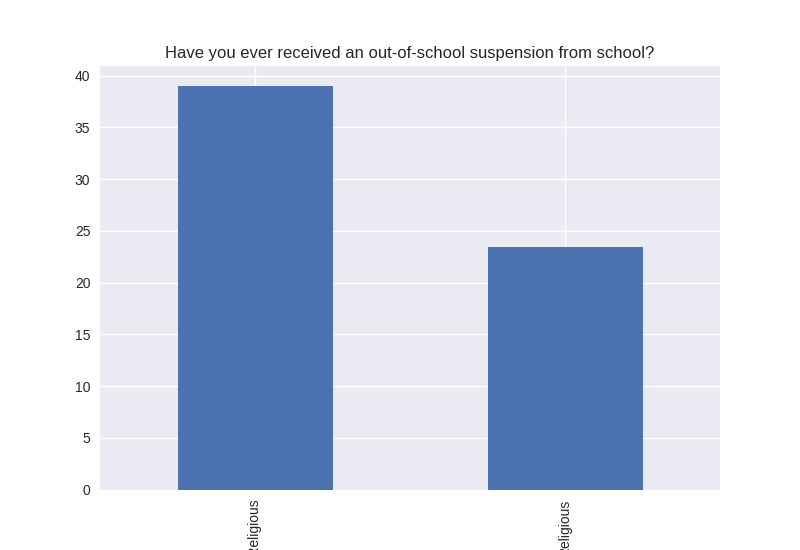
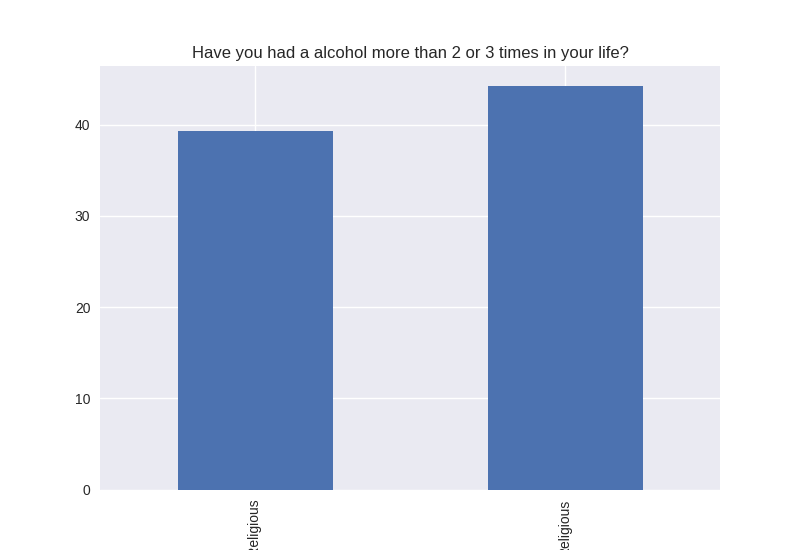
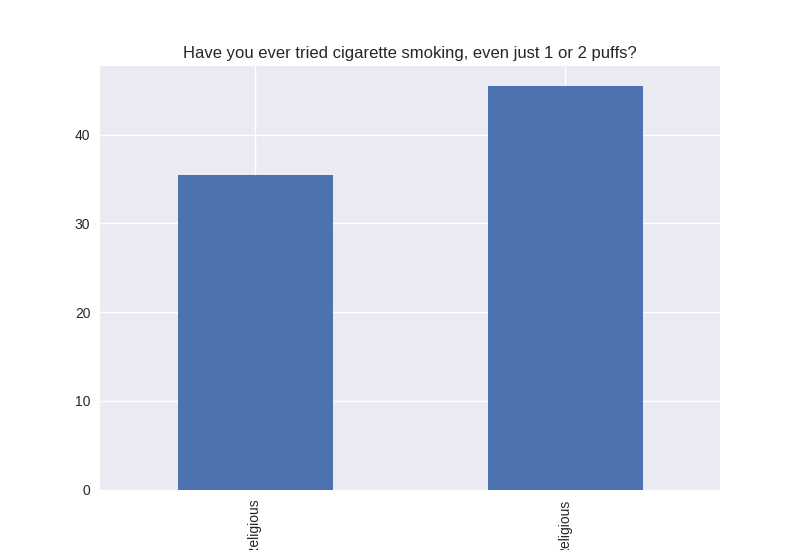
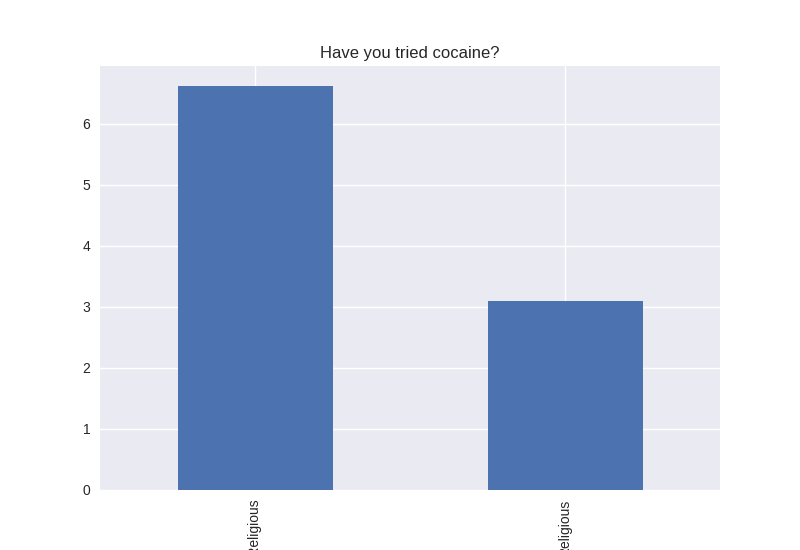
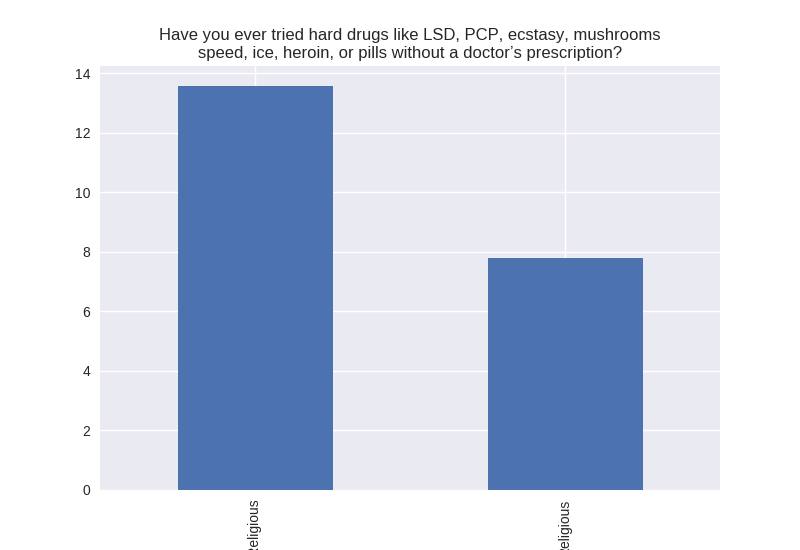
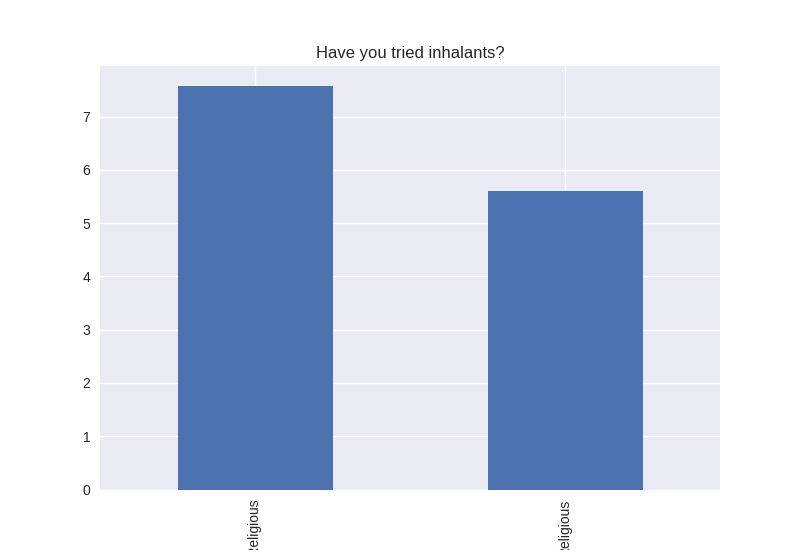
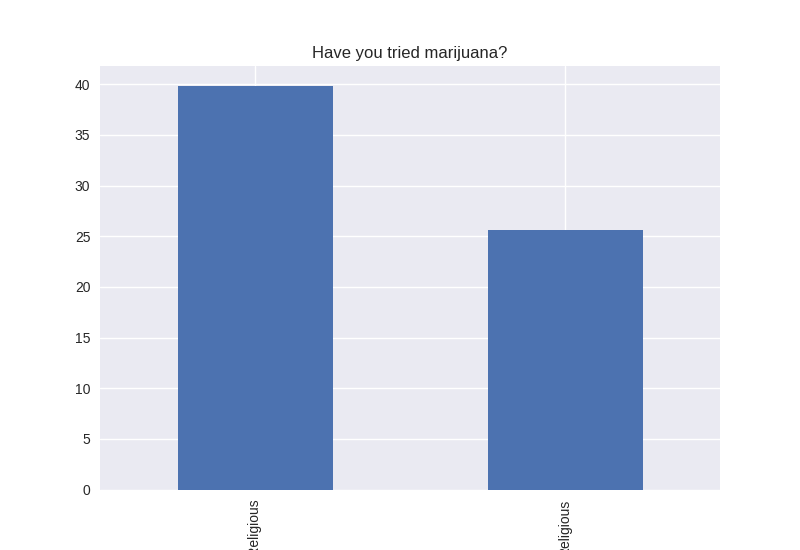
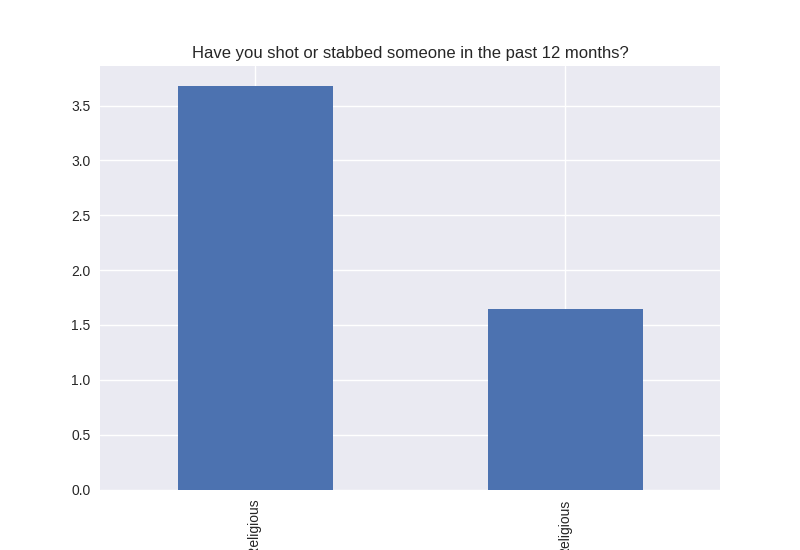
Non-religious vs Religious Responses (Bivariate Analysis)
Digging deeper into the population, I separated the non-religious from the religious and compared the percentages of negative responses (i.e. answered yes to causing property damage) within each group. I found that in almost all cases the non-religious group was more likely to respond negatively to the questions asked. The two areas where religious adolescents were more likely to engage in risky behaviors was drinking alcohol and smoking cigarettes.
Graphical Analysis
Note the y axis is percentage (100 point scale). The labels were cut off for some reason, but the non-religious on on the left and the religious on the right.
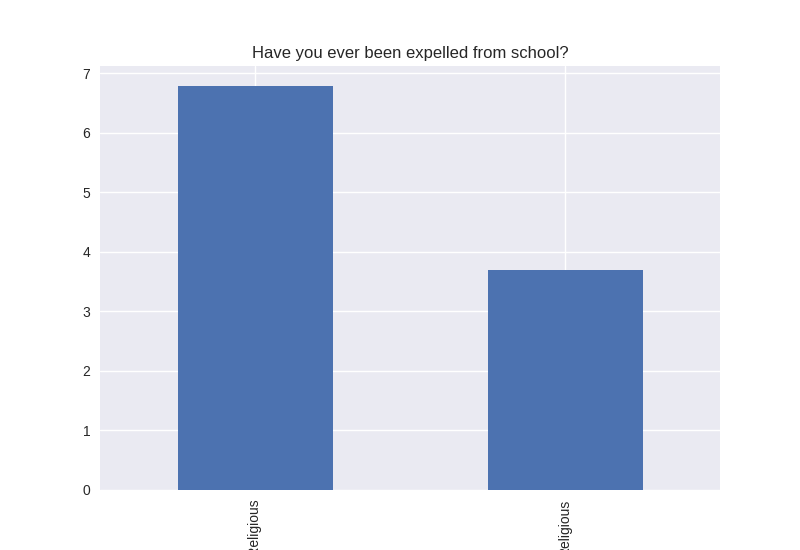
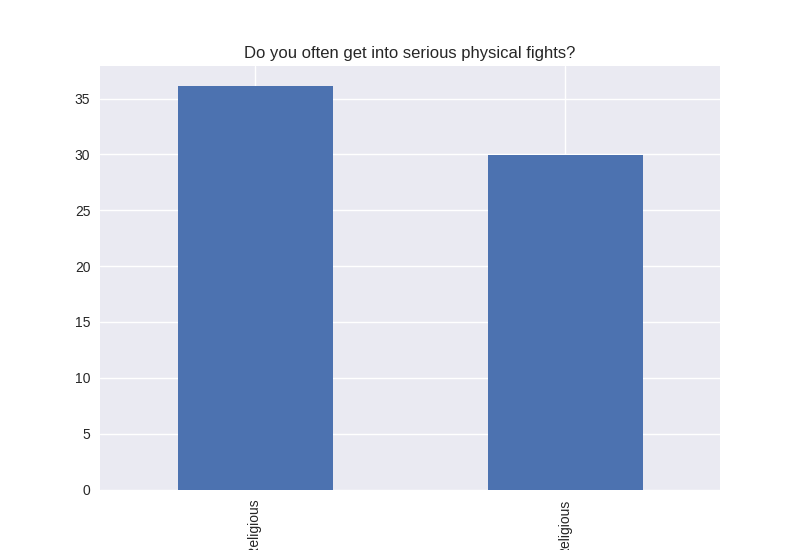
Python Code
import pandas as pd
import numpy as np
import seaborn as sb
import matplotlib.pyplot as plt
# Bug fix for display formats to ovoid run time errors.
pd.set_option('display.float_format', lambda x: '%f'%x)
# Read in data.
data = pd.read_csv('addhealth_pds.csv', low_memory=False)
data['H1TO30'] = pd.to_numeric(data['H1TO30'])
data['H1TO37'] = pd.to_numeric(data['H1TO37'], errors='coerce')
data['H1TO40'] = pd.to_numeric(data['H1TO40'], errors='coerce')
"""
Some Data Management
Creating new variables for questions where 0 means no, and 1 - 18
is an age in which the activity occured.
"""
tried_index = {0:'Not Tried', 1:'Have Tried'}
data.loc[:,'H1ED7'] = data.loc[:,'H1ED7'].replace([' ', '6','8'], np.nan)
data['H1ED7'] = data['H1ED7'].dropna()
data['H1ED7'] = data['H1ED7'].map({'0':'Not Suspended', '1':'Suspended'})
data.loc[:,'H1ED9'] = data.loc[:,'H1ED9'].replace([' ', '6','8'], np.nan)
data['H1ED9'] = data['H1ED9'].dropna()
data['H1ED9'] = data['H1ED9'].map({'0':'Not Expelled', '1':'Expelled'})
data.loc[:,'H1TO1'] = data.loc[:,'H1TO1'].replace([6,8,9], np.nan)
data['H1TO1'] = data['H1TO1'].dropna()
data['H1TO1'] = data['H1TO1'].map(tried_index)
data.loc[:,'H1TO12'] = data.loc[:,'H1TO12'].replace([6,8,9], np.nan)
data['H1TO12'] = data['H1TO12'].dropna()
data['H1TO12'] = data['H1TO12'].map(tried_index)
data.loc[:,'TRYPOT'] = pd.cut(data.H1TO30, [-1,0,18])
data.loc[:,'TRYPOT'] = data.loc[:,'TRYPOT'].replace([96,98,99], np.nan)
data['TRYPOT'] = data['TRYPOT'].dropna()
data.loc[:,'TRYCOKE'] = pd.cut(data.H1TO34, [-1,0,18])
data.loc[:,'TRYCOKE'] = data.loc[:,'TRYCOKE'].replace([96,98,99], np.nan)
data['TRYCOKE'] = data['TRYCOKE'].dropna()
data.loc[:,'TRYINH'] = pd.cut(data.H1TO37, [-1,0,18])
data.loc[:,'TRYINH'] = data.loc[:,'TRYINH'].replace([96,98,99], np.nan)
data['TRYINH'] = data['TRYINH'].dropna()
data.loc[:,'TRYHARD'] = pd.cut(data.H1TO40, [-1,0,18])
data.loc[:,'TRYHARD'] = data.loc[:,'TRYHARD'].replace([96,98,99], np.nan)
data['TRYHARD'] = data['TRYHARD'].dropna()
data.loc[:,'PROPD'] = pd.cut(data.H1DS2, [-1,0,5])
data.loc[:,'PROPD'] = data.loc[:,'PROPD'].replace([6,8,9], np.nan)
data['PROPD'] = data['PROPD'].dropna()
data.loc[:,'SHOPL'] = pd.cut(data.H1DS4, [-1,0,5])
data.loc[:,'SHOPL'] = data.loc[:,'SHOPL'].replace([6,8,9], np.nan)
data['SHOPL'] = data['SHOPL'].dropna()
data.loc[:,'FIGHT'] = pd.cut(data.H1DS5, [-1,0,5])
data.loc[:,'FIGHT'] = data.loc[:,'FIGHT'].replace([6,8,9], np.nan)
data['FIGHT'] = data['FIGHT'].dropna()
data.loc[:,'SELLD'] = pd.cut(data.H1DS12, [-1,0,5])
data.loc[:,'SELLD'] = data.loc[:,'SELLD'].replace([6,8,9], np.nan)
data['SELLD'] = data['SELLD'].dropna()
data.loc[:,'WEPVI'] = pd.cut(data.H1FV8, [-1,0,2])
data.loc[:,'WEPVI'] = data.loc[:,'WEPVI'].replace([6,8,9], np.nan)
data['WEPVI'] = data['WEPVI'].dropna()
data.loc[:,'SUATM'] = pd.cut(data.H1SU2, [-1,0,5])
data.loc[:,'SUATM'] = data.loc[:,'SUATM'].replace([6,7,8,9], np.nan)
data['SUATM'] = data['SUATM'].dropna()
question = {
'H1ED7' : 'Have you ever received an out-of-school suspension from school?',
'H1ED9' : 'Have you ever been expelled from school?',
'H1TO1' : 'Have you ever tried cigarette smoking, even just 1 or 2 puffs?',
'H1TO12' : 'Have you had a alcohol more than 2 or 3 times in your life?',
'TRYPOT' : 'Have you tried marijuana?',
'TRYCOKE' : 'Have you tried cocaine?',
'TRYINH' : 'Have you tried inhalants?',
'TRYHARD' : 'Have you ever tried hard drugs like LSD, PCP, ecstasy, mushrooms\n\
speed, ice, heroin, or pills without a doctor’s prescription?',
'PROPD' : 'In the past 12 months, how often did you deliberately damage\n\
property that didn’t belong to you?',
'SHOPL' : 'Have you ever shoplifted?',
'FIGHT' : 'Do you often get into serious physical fights?',
'SELLD' : 'Do you sell drugs?',
'WEPTH' : 'Have you threatened someone with a gun or knife in the past 12 months?',
'WEPVI' : 'Have you shot or stabbed someone in the past 12 months?',
'H1SU1' : 'During the past 12 months, did you seriously think about suicide?',
'SUATM' : 'During the past 12 months, did you attempt suicide?'
}
NO_RELIGION = 0
UNIMPORTANT_REL = 4
REFUSE_IMPORTANT_REL = 6
DONT_KNOW_IMPORTANT_REL = 8
REFUSE_REL = 96
DONT_KNOW_REL = 98
NA_REL = 99
"""
Religious and non-religious subsets.
"""
non_religious = data[
(data['H1RE1'] == NO_RELIGION) |
(data['H1RE1'] == DONT_KNOW_REL)
]
religious = data[
(data['H1RE1'] != NO_RELIGION) &
(data['H1RE1'] != DONT_KNOW_REL) &
(data['H1RE1'] != REFUSE_REL) &
(data['H1RE1'] != UNIMPORTANT_REL) &
(data['H1RE4'] != REFUSE_IMPORTANT_REL)
]
def dist(var):
dist = data.loc[:,var].value_counts(sort=True, normalize=True)
dist.index = ['pos', 'neg:']
print(dist * 100)
def desc(var):
data[var] = data[var].astype('category')
print(data[var].describe())
def univarGraph(var):
counts = data[var].value_counts(normalize=True)
counts.index = ['pos', 'neg']
counts.plot(kind='bar', title=question[var])
plt.show()
def bivarGraph(var):
nrel_counts = non_religious[var].value_counts(normalize=True)
rel_counts = religious[var].value_counts(normalize=True)
nrel_counts.index = ['pos', 'neg']
rel_counts.index = ['pos', 'neg']
nrel_neg = nrel_counts.to_dict()['neg']*100
rel_neg = rel_counts.to_dict()['neg']*100
suspend = np.array([nrel_neg, rel_neg])
df = pd.DataFrame(suspend, index=['Non Religious', 'Religious'])
df.plot(kind='bar', legend=False, title=question[var])
plt.show()
vars = ['H1ED7', 'H1ED9', 'H1TO1', 'H1TO12', 'TRYPOT', 'TRYCOKE', 'TRYINH',
'TRYHARD', 'PROPD', 'SHOPL', 'FIGHT', 'SELLD', 'WEPVI', 'SUATM']
"""
Total number of participants.
"""
print('-----------------------------------------')
print('# of participants: %d' % (data.shape)[0])
print('-----------------------------------------')
print('')
"""
Total number in non-religious group.
"""
num_non_religious = (non_religious.shape)[0]
print('-----------------------------------------')
print('# of non-religious individuals: %d' % num_non_religious)
print('-----------------------------------------')
print('')
"""
Total number in non-religious group.
"""
num_religious = (religious.shape)[0]
print('-----------------------------------------')
print('# of religious individuals: %d' % num_religious)
print('-----------------------------------------')
print('')
for var in vars:
print('Analysis for "' + question[var] + '"')
print('Distribution:')
dist(var)
print()
print('Discription:')
desc(var)
print()
for var in vars:
univarGraph(var)
for var in vars:
bivarGraph(var)
Absence of Religiosity and Negative Outcomes
Coursera Data Analysis and Visualization Week 1
According the Gallop Organization religious devotion and practice is in decline in America. It is my assumption that adults who are not religious will not transmit religiosity to their children. If this is the case, it could have an effect on the positive and negative factors associated with religion.
Using the National Longitudinal Study of Adolescent Health (Add Health) survey results – a representative sample of adolescents in grades 7-12 in the United States – I seek to answer the question of whether or not religiosity is associated with negative outcomes (defined later). If religion is negatively associated with negative outcomes, we can then expect this trend in religiosity to be beneficial for individuals.
However, if the opposite is true (i.e. religion is positively associated with negative outcomes – i.e. protective against negative outcomes), this research could start a discussion concerning this trend in the American population regarding religiousness.
SQLite3 Database Quick Create with Bash
In this post, I will document a couple of cases where one can quickly create an SQLite3 database by issuing commands in a Bash shell (the default terminal shell in Linux and Mac OS X).
Case 1: Create a database with a table for images containing rows/tuples with the image url and a caption for the image. The images are in a directory located in resources/img/gallery, and the database will be stored in a directory at resources/sql.
Creating the database
touch resources/sql/img.db.sql
The touch command is used to change (update) the given file’s timestamp, but if the file (in this case resources/sql/img.db.sql) does not exist it will be created. Now, to make things easier to fit and read on a single command line, I’ll create a Bash variable the stores the command to access the SQLite3 database.
db='sqlite3 resources/sql/img.db.sql'
Creating and populating the img table
echo "CREATE TABLE img (url TEXT, caption TEXT);" | $db
for x in `ls resources/img/gallery`; do
echo "INSERT INTO img (url,caption) VALUES ('resources/img/gallery/$x','Insert Caption...');" | $db
done
Now the table should be created and populated with the desired content (captions to be inserted at a later time).
echo "SELECT * FROM img;" | $db resources/img/gallery/0001.jpg|Insert Caption... resources/img/gallery/0002.jpg|Insert Caption... resources/img/gallery/0004.jpg|Insert Caption... resources/img/gallery/0006.jpg|Insert Caption... ... remaining output omitted ...
More cases to come…
Bash Programming – String Replace
Syntax for string replace operations in BASH:
String Splice:
${parameter:offset:length}
Find and Replace:
${string/pattern/replacement}
Replace all:
${string//pattern/replacement}
Work with all Files in a git Repo
Work with All files in git Repo
To add all changed files use the -A argument on the command line.
git add -A
To commit all changed and staged files and changes:
git commit -a
or, if you want to enter a command line message:
git commit -am "your commit message here"